Agora você pode ter a sua própria IA local com seus recuros, neste tutorial vamos fazer a instalação do Ollama utilizando os modelos Llama 3.2 de 3B e Codegemma de 7B com o OpenWebUI via Docker no Ubuntu 24.04 LTS.
Pré-requisitos:
- Sistema Operacional: Ubuntu 24.04 LTS.
- Docker: Instale o Docker e Docker Compose.
- Modelos Ollama: Llama 3.2 de 3B e Codegemma de 7B.
- Requisitos de hardware: Tenha no mínimo 16 GB de RAM e espaço em disco suficiente para os modelos (~30GB).
Passo 1: Atualização do sistema
Atualize o sistema para garantir que tudo esteja funcionando corretamente.
sudo apt update && sudo apt upgrade -yPasso 2: Instalação do Docker e Docker Compose
Se o Docker ainda não estiver instalado, execute os seguintes comandos:
Instale o Docker:
sudo apt install docker.io -yAdicione seu usuário ao grupo Docker
sudo usermod -aG docker $USERInstale o Docker Compose:
sudo apt install docker-compose -yPasso 3: Instalação do Ollama com Docker
Baixe a imagem do Ollama usando Docker: Crie um arquivo docker-compose.yml para configurar o Ollama e o OpenWebUI.
version: '3'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama-server
ports:
- "11434:11434"
volumes:
- ./models:/app/models
command: ollama serve
environment:
- OLLAMA_MODELS_DIR=/app/models
openwebui:
image: abdel/openwebui:latest
container_name: openwebui
ports:
- "8080:8080"
depends_on:
- ollama
environment:
- OLLAMA_SERVER_URL=http://ollama-server:11434Suba os containers: Navegue até a pasta onde o docker-compose.yml foi salvo e execute:
docker-compose up -dPasso 4: Download dos modelos Llama 3.2 e Codegemma
Dentro do container Ollama, faça o download dos modelos:
Acesse o container do Ollama:
docker exec -it ollama-server bashBaixe os modelos Llama 3.2 e Codegemma:
ollama pull llama:3.2
ollama pull codegemma:7BVerifique se os modelos foram baixados corretamente:
ollama modelsPasso 5: Configuração do OpenWebUI
Com o OpenWebUI rodando no container, você pode acessá-lo via navegador no endereço:
http://<IP_do_seu_servidor>:8080Configure criando uma conta e ajuste suas configurações.
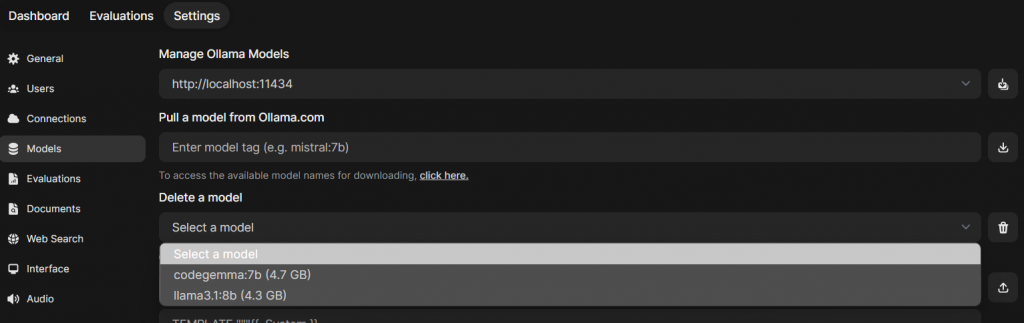
Dentro do Open WebUI, vá em Admin Panel, em seguida Settings e Models, veja se os modelos foram baixados corretamente e estão aparecendo como na tela abaixo.